pythonでスイングbotを構築する過程で、初心者らしく色々疑問や壁にぶつかっているので、備忘も兼ねて記録。
疑問
ローソク足を追加する際、コードの簡便さ・処理速度の観点でベターな方法は次のどちらか。
- for文ループ
- DataFrameでの差分抽出
ローソク足をベースにした戦略をbotに組む際、どのようにローソク足を最新化することがベターなのかを初心者が調べます。
文章量の関係上、まずは実現方法を当記事にて書いて、次の記事で処理速度を調べ、2つの記事を以て、よりベターな実装方法の結論を出します。
ちなみに、上の疑問に書いた以外の選択肢には気づきもしていないので、いろんな良い方法があれば教えてください。
前提として、1のfor文ループは既に実装したことがあるので、実現方法にはほぼ触れません。一方で、2は執筆開始段階で実現方法が分かっていないので、実現方法から試行錯誤します。
試行錯誤過程も記載しているので、かなり右往左往した内容になります。
いざ!
目次
for文ループの実装
元々は1のパターンが簡単だったので、for文でやってました。
恥ずかし気もなく晒すと次のような感じ。
if ( len(price_list) ) > 0: #差分追加。price_listにはローソク足を貯めているので0より大きいなら差分追加と判定。
for i in data["data"]:
if ( int(int(i['openTime']) / 1000) > price_list[-1]["close_time"] ):
price_list.append({ "close_time" : int( int(i['openTime']) / 1000 ),
"close_time_dt" : datetime.fromtimestamp(int(i['openTime']) / 1000).strftime('%Y/%m/%d %H:%M'),
"open_price" : int(i['open']),
"high_price" : int(i['high']),
"low_price" : int(i['low']),
"close_price" : int(i['close']),
"volume" : float(i['volume']) })
else: #新規追加。price_listが0なら新規でローソク足を取得するパターンと判定してappendによる単純追加。
for i in data["data"]:
price_list.append({ "close_time" : int(int(i['openTime']) / 1000),
"close_time_dt" : datetime.fromtimestamp(int(i['openTime']) / 1000).strftime('%Y/%m/%d %H:%M'),
"open_price" : int(i['open']),
"high_price" : int(i['high']),
"low_price" : int(i['low']),
"close_price" : int(i['close']),
"volume" : float(i['volume']) })
一応コードの意図を記載しますと、前提として上記コードの前には、取引所からapiで最新ローソク足を取り込む処理(data)があります。
過去に取得してきたローソク足を貯めこんでいるリストがprice_listで、ネスト構造で複数期間分保持されることが想定されています。
よって、price_listの要素が0より大きいなら過去のローソク足を貯めこんでいて、0なら何も貯めこんでいないことになります。
この条件分岐を入り口に、要素が0より大きいときは、for文ループで新しく取得したローソク足のopenTimeが既保持分より大きいかを判定し、大きいものは未保持なので追加することで差分抽出を実現しています。
反対に要素が0のときは新規取得時なので単純追加させています。
わざわざfor文でopenTimeを比較させているのは、ローソク足の更新タイミングが厳密には分からずに、既に保持している分を再度取得してきてしまう可能性を考慮したためです。
とまぁ、以上のように、過去から最新までのローソク足一式を持ったprice_listを一応作成しておりました。
が、初心者ながらに、コードが不細工だとは思っていた。
なんというか力技すぎる。
よって、第2案。
元々保持しているローソク足も、最新で取ってきたローソク足もDataFrame化して、マトリクス表的に差分抽出・追加できないか、と考えました。
なんかスマートに出来そうな予感がしたので。
ここからは学びと復習を兼ねて細かく実現方法を書いていきます。
陥った罠も含めて書くので右往左往します。
DataFrameでの差分抽出の実装
まず、過去分ローソク足想定のdf1を用意。

これに対して、最新のローソク配信で次の2つのローソク(df2)が取得されたとする。

df1の2とdf2の0は重複しています。
なので、目指すところは、df2の1だけを差分として抽出してdf1に追加してあげること。
df2の中で、df1には無いものを追加したいので、まずはisin関数を使って、「df2の中でdf1に含まれないもの」を調べる。
print(~df2.isin(df1))
結果はこうなる。

isinはbool型で返ってくる。
よって、結果としては、「df2のindex1のlowとopenだけ重複(False)していて、他は重複していない。」になる。
ちなみにコードに書いた「~」は、「ではない」という否定の意味らしい。
今回色々調べてみて初めて知りました。
これでは望んだ結果になっていない。
正確に調べたわけではないけれど、どうやらisin関数は対応するindex・columnでの比較しかしてくれないようである。
つまり表の同じ位置にあるもの同士の比較しかしてくれない。
df2のindex1のlowとopenは、たまたまdf1のindex1のlow・openと一緒なので、こいつだけが重複と判定されました。
しかしそうではない。
やりたいのは、行単位で差分を抽出したい。
色々調べた結果、isin関数に辞書型のリストのネスト構造のやつで渡すとindexとcolumnの対応付けから解放されるらしい。
よってdf1にto_dictのメソッドを使って、辞書型に変換し、オプションでリストのネスト構造になるようにオプションに"list"を指定する。
早速実行。
print(~df2.isin(df1.to_dict("list")))
前提として、df1.to_dict("list")にしたdf1は下のような構造になっている。
![]()
見にくいけれど、列名がkeyになっていて、各値がリスト化されている。
んで、結果。

辞書型でisin関数に渡すとkeyの対応付けは見るようなので、やっていることは「df2の各列の値が、一致するdf1のkeyのリストの中に含まれているか否か」ということらしい。
よって、df2のcloseのindex=0の6764920は、df1のcloseのリストの中に含まれているので、False(指定条件が含まれないもの(~isin)のため)が返ってきていて、index=1の6769879は含まれないからTrueが返ってきている。
ちなみに少し脱線して、to_dictメソッドでオプションをつけずに渡すと、df1は辞書のネスト構造になる。
print(df1.to_dict()) print(~df2.isin(df1.to_dict()))
結果はこうなる。

全部含まれないという判定。
ここらへんが、どうやって参照しにいっているのか正確に理解できなかったのですが、まずdf1.to_dict()とすると、列名をkeyにした辞書型になって、更にindexをキーにした辞書型がネストされる。
全部含まれないと判定されたのは、df2が含まれるかを検索にいったときに、おそらくcloseというキーの一致までは確かめられても、次のindexのキー一致が確認できない(df2の方はcloseというkeyしか持っておらず、0とか1とかのkeyは持ってない)ためではないかと推測しています。
ここらへん正確な知識ある方、教えてください。
話を戻します。
よくよく考えたら、closeやopen等の値は、ローソク足によっては重複がありうるので、検索にいくこと自体が妥当ではない。
時刻(openTime)で重複を確認するのが妥当でしょう。
ということで、元々のコードを更に改造。
print(~df2["openTime"].isin(df1.to_dict("list")["openTime"]))
両方にopenTimeの条件を加えて、openTimeだけでのisin処理にしました。
結果。

df2のindex=1が含まれないよ、という望んだ結果が得られました。
よって、これを条件としてdf2[]で囲んであげて、実際の値を抽出する。
print(df2[~df2["openTime"].isin(df1.to_dict("list")["openTime"])])
結果、openTime比較により、df1に含まれないdf2の実際の値を取り出すことに成功。

長かった・・・・。
しかし、ここで終わりではない。
例えば常に最新の50本のローソク足をdf1に保持しておくコードを書いていたとする。
一方で、取引所からローソク足を取得(df2)した場合、デフォルトで200本取得されるとする。
そうすると、最新差分以外にも、もっと古いところでの差分も検知される可能性がある。
上の例でいえば、50本より前の差分は意図して保持させていないことになるので除外して、最新差分だけにしたい。
print(df2[(~df2["openTime"].isin(df1.to_dict("list")["openTime"]) & (df2["openTime"] > df1.iloc[-1]["openTime"]))])
コードを更に変更。
&以降の条件部分を追加しました。
即ち、「重複が無く、かつdf1の最新ローソク足のopenTimeより大きいもの」としました。
意図通りに稼働するか実験。
df2を改造して、df1(元々持っているローソク足想定)より前の期間も含むローソク足群にします。
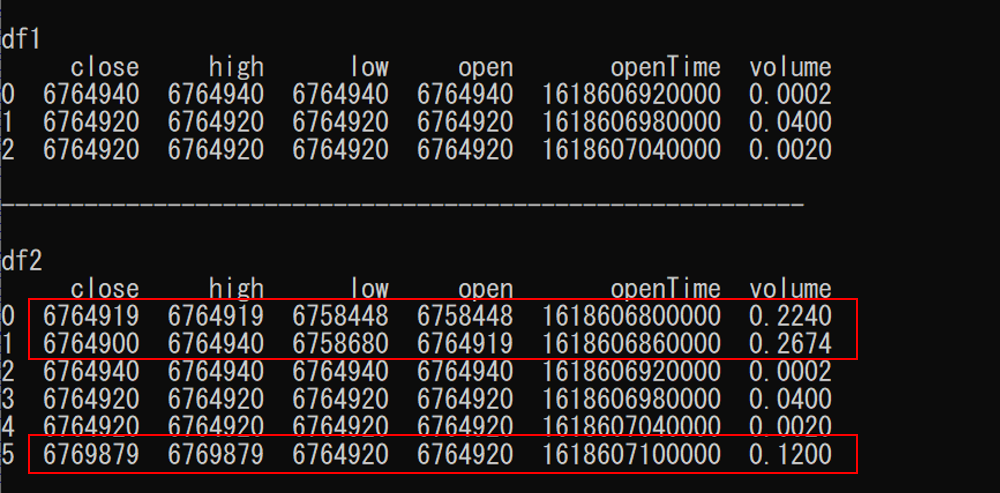
df2は取引所から取ってきたローソク足想定で、赤枠はdf1には持っていない差分想定。
ですが、index=0、1の差分は、df1では敢えて捨てている部分なので、本当にdf1に欲しいのはindex=5の差分のみ。
結果。

問題なく、最新差分だけ取れました。
まとめ
まとめもくそも無いんですが、ようやくDataFrameで差分抽出する方法に辿りつけました。
本当にこの記事を書くまではやり方を知らなかったんですが、調べて良かった。
元のローソク足群の形がどうなっているかにもよりますが、差分抽出処理だけ抜き出すと、DataFrameによる差分抽出の方が圧倒的に簡便にコードが書けますね。
保守もしやすそう。
よって、コードの簡便さの面で圧倒的に2.DataFrameでの差分抽出が魅力的。
後は処理速度の問題ですが、こちらはより実践的に調べたい。
おそらくfor文ループで差分を取るなら、元のローソク足群は辞書型をネストしたリスト構造で持つことになるでしょうし、DataFrameで差分を取るなら、最初からDataFrameにした形でローソク足群を持つことになる気がします。
この前提を踏まえた処理速度の計測を次回やっていきます。
こんな些末なことからやっていたら、bot製作がマジで進まない気もしますが・・・まあいいか。